
Clustering and Segmentation Approaches for Big Data Filtering
- 1 minSummer Undergraduate Research Experience (SURE) is a program held by IIT's College of Computing every summer. Undergraduates spend a few months working with professors and graduate students on research in computer science and applied mathematics. In 2021, I worked with Professor Lulu Kang on her research in data filtering using unsupervised machine learning.

I examined prior methods in filtering information in large datasets, which have become more complex and harder to analyze due to modern sensing systems. These methods frame data reduction as a minimization problem: minimizing redundant information, while still maintaining the most important information.
Building off of past research, I studied a data filtering method proposed by Professor Kang, which relied on k-means clustering and sampling methods. This algorithm splits data by time indices and optimally clusters each segments. It repeatedly samples from each cluster, until the information loss falls below a given tolerance, and then reconstructs the newly filtered dataset.
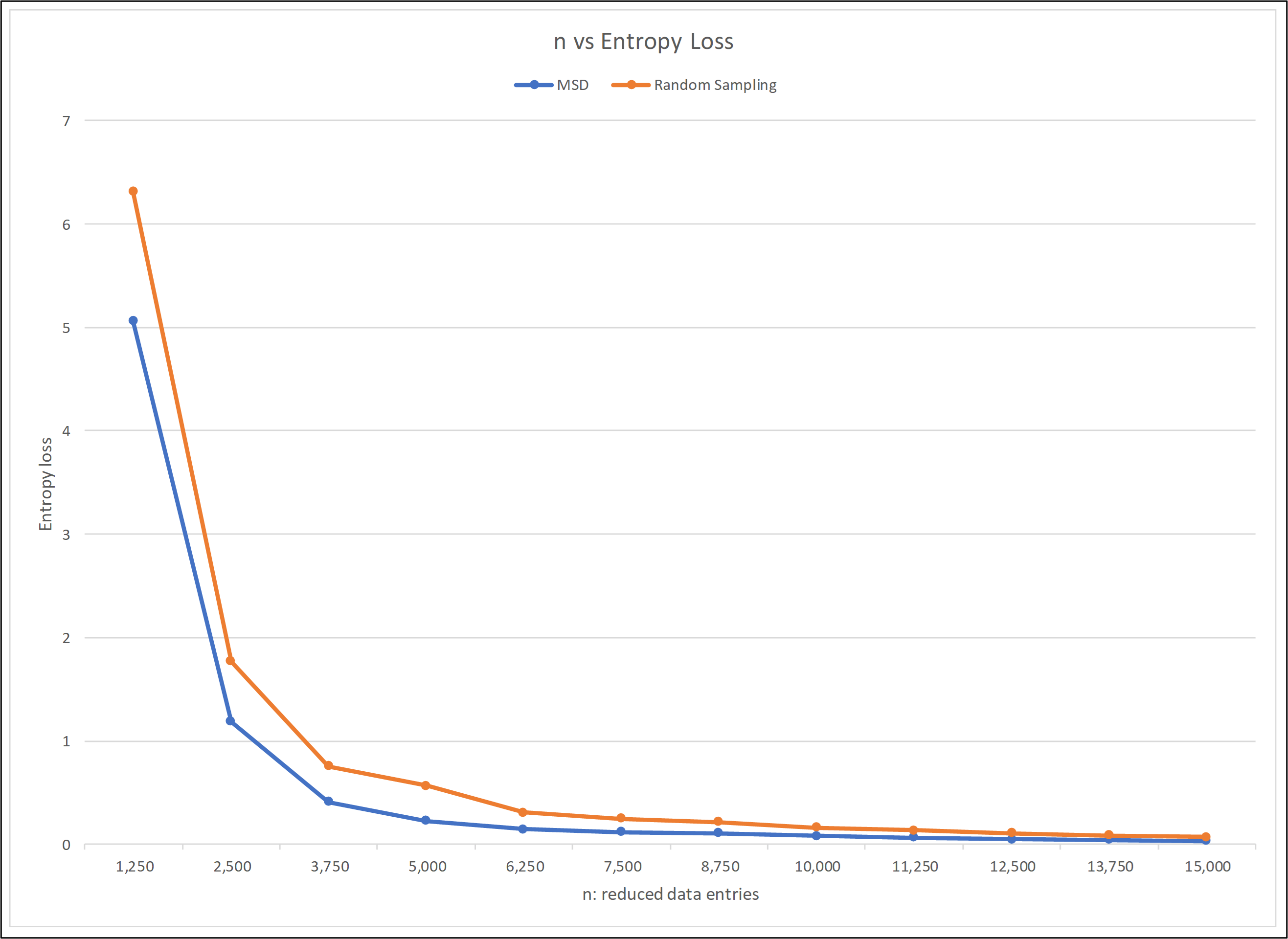
I coded this algorithm in MATLAB. For a case study, I used a dataset consisting of nearly 25,000 data entries and 32 response variables, provided by a consumer goods corporation. I experimented with different parameters, such as tolerance and optimal filtering ratios. Finally, I compared the performances of this method and random sampling.
At the end of the seven weeks, I gave a presentation, "Clustering and Segmented Approaches for Big Data Filtering," on my results to the SURE program.

Kaylee J. Rosendahl
Searching for that asymptote